
Summarize this article with:
- Retrieval-Augmented Generation (RAG) combines an LLM with an external knowledge base or database, enabling the model to retrieve and incorporate real-time or highly specific data that it may not...
- Fine-Tuning involves training a pre-existing LLM on a specific dataset to improve its performance for certain tasks or domains.
- RLHF can refine the model's performance by rewarding it for generating outputs that align better with human expectations.
- Good for : Tasks that involve subjective judgment, such as conversational agents, content generation, or creative writing.
- Fine-tuning the LLM using these labeled examples, allowing the model to learn the mapping between inputs and the target outputs.
As generative AI becomes integral to various domains, fine-tuning Large Language Models (LLMs) is key to optimizing performance and tailoring models for specific use cases. By enhancing accuracy and relevance, fine-tuning ensures AI aligns with unique requirements. This article highlights the top 10 tools and practices to streamline the process and maximize results.
What is Finetuning LLM?
Fine-tuning in machine learning is a technique that involves adapting a pre-trained Large Language Model (LLM) to perform more effectively on a specific task or within a particular domain.
Fine-tuning is one of the most powerful and permanent ways to customize LLMs. It differs from other customization techniques in that it alters the model's parameters through additional training, embedding specialized knowledge directly into the model.
However, it requires more time, resources, and expertise compared to simpler customization techniques like prompt engineering.
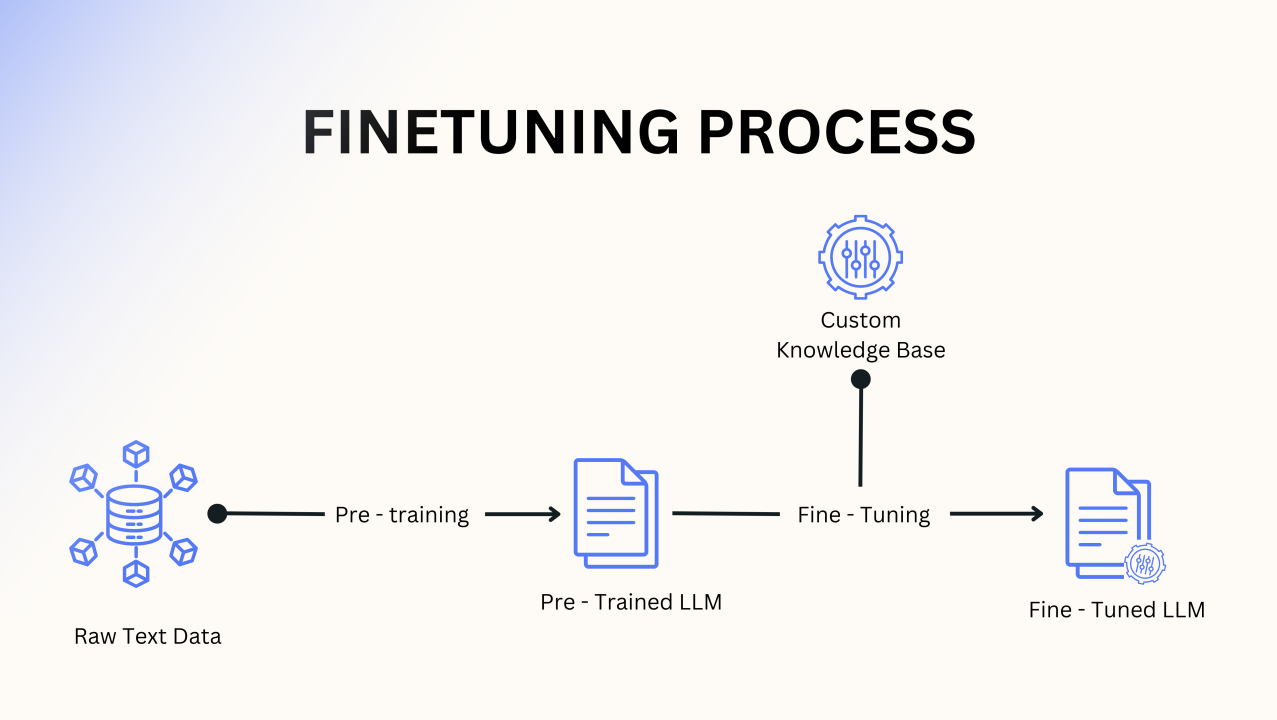
While prompting can nudge an LLM in the right direction, fine-tuning offers a far more dependable way to achieve the desired outcomes, with fewer hiccups on specific tasks.
Building a foundation model from scratch is a monumental task, requiring vast resources and data. Fine-tuning, however, starts with an already trained LLM and allows you to mold it to your needs using your own data.
This delivers more precise, task-specific AI performance without the astronomical computational costs of starting from square one.
Most modern LLMs, like ChatGPT, Claude, and Llama, are built for versatility. They serve as impressive generalists but tend to lack in-depth expertise in specialized fields—such as pharmaceutical research or a company's internal legal documents.
Fine-tuning addresses this gap by adding a layer of specialized knowledge, enhancing their performance in these areas.
Methods to Customize an LLM
As we said before fine-tuning involves modifying a pre-trained LLM to enhance its performance on specific tasks or datasets but there are other approaches to customizing LLMs, including:

1. Prompt Engineering
Prompt engineering involves crafting specific and carefully structured prompts to guide the model's output in a desired direction. By adjusting the wording, structure, or providing additional context in the prompt, users can extract more relevant, detailed, and accurate responses from the model.
It is a key practice for leveraging LLMs effectively without modifying the model itself. This can be particularly useful when trying to make the model understand nuances, such as tone, style, or specific instructions that need to be followed for successful task completion.
- Good for: Testing basic use cases, quick deployment.
- Limitations: Restricted by context window size, less reliable for complex tasks.
2. Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) combines an LLM with an external knowledge base or database, enabling the model to retrieve and incorporate real-time or highly specific data that it may not have encountered during its training.
The model first retrieves relevant documents, articles, or facts from the database before generating a response, effectively combining generation with a knowledge retrieval step. This reduces the likelihood of the model "hallucinating" incorrect or fabricated information, especially when queried about facts outside of its training data.
- Good for: Introducing new information not in the model's training data.
- Limitations: Ineffective for reducing token usage or defining structured outputs.
3. Fine-Tuning
Fine-Tuning involves training a pre-existing LLM on a specific dataset to improve its performance for certain tasks or domains. Fine-tuning customizes the model's response style, accuracy, and behavior, making it more suitable for particular use cases.
Fine-tuning adapts a model to perform well in particular areas, such as medical diagnoses, technical writing, customer service, or legal analysis. Additionally, fine-tuning can adjust the model's tone, style, and behavior to match specific goals or company standards.
- Good for: Teaching complex tasks, customizing output structure and style.
- Limitations: Not suitable for adding entirely new knowledge.
4. Reinforcement Learning with Human Feedback (RLHF)
Reinforcement Learning with Human Feedback (RLHF) uses human-curated feedback to improve model responses, particularly for tasks involving subjective or stylistic decisions.
RLHF can refine the model's performance by rewarding it for generating outputs that align better with human expectations. It's a form of iterative improvement and is often seen as a subtool of fine-tuning.
- Good for: Tasks that involve subjective judgment, such as conversational agents, content generation, or creative writing. It's also useful for aligning the model's behavior with specific user preferences or ethical guidelines.
- Limitations: Requires a consistent and high-quality feedback loop, which can be time-consuming and resource-intensive. RLHF might not be effective for highly technical tasks where accuracy is more critical than subjective alignment.
Finetuning methods
There are multiple methods to finetune an LLMs, but two prominent approaches have emerged: reinforcement learning with human feedback (RLHF) and supervised learning.
1. Reinforcement learning with human feedback (RLHF)
When the output of an LLM is complex and difficult for users to describe, the RLHF approach can be highly effective. This method involves using a dataset of human preferences to tune the model.
Key steps of RLHF
The strength of RLHF lies in its ability to capture nuanced human feedback and preferences, even for outputs that are challenging to articulate. By learning directly from human choices, the model can be shaped to produce results that are more meaningful and valuable to end-users.
- Gather feedback from humans on the model's outputs. This feedback takes the form of choices between different output options.
- Use this human preference data to fine-tune the model through reinforcement learning. The model learns to generate outputs that are more aligned with human preferences.
RLHF Example
input_text : Create a description for Plantation Palms.
candidate_0 : Enjoy some fun in the sun at Gulf Shores.
candidate_1 : A Tranquil Oasis of Natural Beauty
choice: 0
2. Supervised Learning
In contrast, the supervised learning approach to fine-tuning LLMs is better suited for models with outputs that are relatively straightforward and easy to define.
Supervised Learning method
The supervised learning approach is particularly useful when the desired output can be clearly specified, such as in tasks like text classification or structured data generation. By providing the model with exemplary input-output pairs, it can learn to reliably reproduce the expected results.
- Curating a dataset of labeled examples that demonstrate the desired output of the model.
- Fine-tuning the LLM using these labeled examples, allowing the model to learn the mapping between inputs and the target outputs.
Supervised Learning Example
Prompt : Classify the following text into one of the following classes: [business, entertainment].
Text: Diversify your investment portfolio
Response : business
The choice between RLHF and supervised learning for fine-tuning an LLM depends on the complexity of the model's outputs and the ease with which they can be defined. RLHF is the better option when the outputs are intricate and subjective, requiring nuanced human feedback to guide the model's learning.
Supervised learning, on the other hand, shines when the desired outputs are more straightforward and can be accurately captured in a labeled dataset.
How to Finetune LLMs ?
Fine-tuning a pre-trained model allows it to specialize in a specific task by training it on a smaller, task-specific dataset.
The workflow includes data preparation, model training, evaluation and iteration, and deployment, each of which contributes to the model's optimization for real-world applications.

1. Data Preparation
The first step in fine-tuning is preparing high-quality, labeled data relevant to the task. The quality and diversity of this data will directly impact the performance of the fine-tuned model.
- Gather labeled data that represents the task you want the model to perform.
- Clean the data by removing inconsistencies, duplicates, and irrelevant information.
- Ensure diversity in the data to cover a wide range of inputs and scenarios, which helps the model generalize better.
- Format the data in a standardized structure (e.g., JSONL) for compatibility with the fine-tuning platform.
- Balance the dataset to avoid overrepresentation of certain examples or labels.
2. Model Training
In this step, you'll train the model on the prepared dataset. You'll need to choose the right hyperparameters and monitor the model's progress to ensure it's learning the task effectively.
- Select appropriate hyperparameters such as learning rate, batch size, and number of epochs.
- Train the model on the task-specific examples (usually 50-1000 samples for small tasks).
- Monitor the training process for signs of overfitting or underfitting by analyzing loss and accuracy metrics.
- Adjust hyperparameters like the learning rate or batch size based on the model's performance.
- Experiment with different configurations if the model isn't improving, such as modifying the architecture or training approach.
3. Evaluation and Iteration
Once the model is trained, evaluate its performance on a validation set to see how well it generalizes to new data. Iterative adjustments help improve the model's accuracy and reliability.
- Evaluate performance using metrics like training loss, validation loss, F1 score, or task-specific accuracy (e.g., precision, recall).
- Identify areas for improvement by comparing the model's performance against the desired outcome.
- Refine the model by adjusting hyperparameters, adding more training examples, or improving the quality of the data.
- Iterate through multiple cycles of training and evaluation to fine-tune the model further.
- Test the model's robustness by ensuring it performs well across a variety of inputs and conditions.
4. Deployment
After achieving satisfactory performance, deploy the fine-tuned model into real-world applications, ensuring that it is scalable and easily accessible for end-users.
- Integrate the fine-tuned model into your application or service through an optimized API.
- Monitor model performance in production to identify any issues like latency or inaccuracies.
- Set up a feedback loop for continuous improvement, retraining the model periodically with new data or user feedback.
- Ensure scalability by optimizing the model for speed and efficiency in real-time applications.
- Secure the deployment by implementing access controls and monitoring for potential security risks.
Top 10 Fine-Tuning Tools
1. Eden AI


Eden AI is a full-stack AI platform for developers to efficiently create, test, and deploy AI with a unified access to the best AI models combined with a powerful workflow builder. Eden AI supports fine-tuning AI models from multiple providers, enabling users to customize their models for specific tasks.
Key Features:
- Multi-Provider Support: Fine-tune models from various AI providers, including GPT-4o.
- Customizable Parameters: Adjust epochs and dataset size for tailored results.
- Easy Data Management: Import datasets (e.g., CSV) and create structured prompts effortlessly.
- User-Friendly Interface: Simplifies fine-tuning for all skill level.
Best for: Eden AI is great for deploying customized AI models from multiple providers to meet domain-specific needs and optimize performance.
2. Hugging Face (autotrain)

Hugging Face offers a powerful open-source platform for fine-tuning pre-trained models, making it a go-to for machine learning practitioners.
Key Features:
- Supports a wide range of pre-trained models across multiple frameworks
- Provides extensive libraries for PyTorch and TensorFlow
- Offers easy-to-use training APIs and model repositories
- Supports various fine-tuning techniques like LoRA and full parameter tuning
Best For: Researchers and developers looking for a flexible, open-source solution with extensive model support.
3. Weights & Biases (Wandb)

Weights & Biases is an experiment tracking and model management platform designed to streamline machine learning projects.
Key Features:
- Comprehensive experiment tracking
- Visualization of model performance metrics
- Collaboration tools for team-based machine learning projects
- Support for hyperparameter optimization
- Integrates seamlessly with major ML frameworks
Ideal For: Teams and organizations requiring robust experiment management and collaboration tools.
4. Comet.ml

Comet.ml is an MLOps platform that helps teams track experiments, manage models, and visualize performance.
Key Features:
- Comprehensive model tracking and versioning
- Automatic hyperparameter optimization
- Model performance visualization
- Support for multiple machine learning frameworks
Great For: Organizations needing detailed model management and performance tracking.
5. Entrypoint.AI
Entrypoint.AI is an AI optimization platform for proprietary and open-source language models, offering a no-code approach to fine-tuning.
Key Features:
- Manage prompts, fine-tuning, and evaluations in one place.
- No-code fine-tuning process.
- Supports foundation LLMs with built-in fine-tuning capabilities.
Best For: Users looking for a modern, no-code platform to fine-tune AI models with ease.
Foundation LLMs providers also offer built-in fine-tuning capabilities directly through their APIs and platforms like :
6. OpenAI Fine-Tuning
OpenAI provides a simple API for fine-tuning GPT-3.5 and GPT-4 models, enabling custom training on specific datasets.
Key Features:
- Direct model fine-tuning through OpenAI's API.
- Supports GPT-3.5 and GPT-4 models.
- Custom training on specific datasets.
- Minimal infrastructure required.
- Pricing based on input and output tokens during training.
Best For: Developers looking for a simplified fine-tuning process with minimal setup and infrastructure.
7. Anthropic Claude Fine-Tuning
Anthropic Claude focuses on custom model adaptation through API integration with an emphasis on ethical and safe behavior.
Key Features:
- Custom model adaptation via API.
- Focus on maintaining ethical and safe model behavior.
- Domain-specific contextual learning.
- Responsible AI customization.
Best For: Great for organizations focused on ethical AI deployment with domain-specific needs.
8. Google Cloud Vertex AI

Google Cloud Vertex AI provides an end-to-end machine learning platform for fine-tuning models like PaLM and other Google language models.
Key Features:
- End-to-end machine learning platform.
- Fine-tuning of PaLM and Google language models (Gemini).
- Enterprise-level model customization.
- Integration with Google Cloud's ML ecosystem.
- Advanced monitoring and management tools.
Best For: Ideal for enterprise-level model customization within the Google Cloud ecosystem.
9. Azure OpenAI Service

Microsoft's Azure OpenAI Service offers enterprise-grade fine-tuning capabilities with enhanced security and model governance.
Key Features:
- Supports multiple GPT models.
- Enhanced security and compliance features.
- Seamless integration with Microsoft's cloud infrastructure.
- Advanced access controls and model governance.
Best For: Businesses requiring secure, enterprise-grade AI solutions with robust governance.
10. Cohere

Cohere offers a powerful platform for language model fine-tuning, providing easy integration with a focus on text generation and embeddings.
Key Features:
- Fine-tuning models for text generation and embeddings.
- Models: Command Light
- Simple, easy-to-use API
- Strong performance on classification tasks.
Best For: Perfect for users seeking an easy-to-use API for fine-tuning models with a focus on text-related tasks.
11. AWS Bedrock

AWS Bedrock offers a range of fine-tuning options with models like LLaMA, Cohere, and AWS Titan, with seamless integration into AWS services.
Key Features:
- Fine-tuning and continued pre-training options.
- Support for models like LLaMA, Cohere, and AWS Titan.
- Seamless integration with AWS services.
Best For: Ideal for users already within the AWS ecosystem who require continued fine-tuning capabilities with deep integration.

.jpg)


