.png)
Summarize this article with:
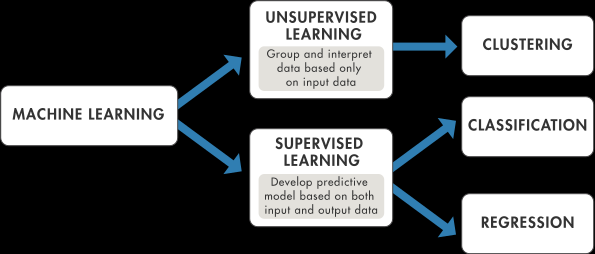
- Models are built, for example, on the basis of regression to create a model allowing numerical prediction (e.g.
- Another type of Machine Learning model is classification.
- AutoML (Automated Machine Learning) allows the support and automation of many steps in the process of creating a Machine Learning model:.
- AutoML permits to a company to realize a Machine Learning project without the expertise of a data scientist or a data science service provider: it thus induces a drastic reduction of the cost of the project.
- Predictive modelling & AutoML: Which AI provider to choose ? enables automation, accuracy improvements, and cost reduction across AI-powered applications.
This article is brought to you by the Eden AI team. We allow you to test and use in production a large number of AI engines from different providers directly through our API and platform. In this article, we test several solutions to generate predictive models for classification or regression with two use cases: Prediction of costs associated with an insured (regression) and attribution or not of a bank credit (classification). Enjoy your reading!
You are a solution provider and want to integrate Eden AI, contact us at : [email protected]
Long before the term “Artificial Intelligence” was coined, mathematics were already being used to analyze numerical data. Many companies became interested in analyzing data for prediction and optimization. Statistical methods such as linear regression have been used for a long time and in many fields.
However, the rise of artificial intelligence, especially Machine Learning, has democratized the use of these statistical methods to form learning algorithms for accurate and automated predictions.
Regression
Models are built, for example, on the basis of regression to create a model allowing numerical prediction (e.g. sales, temperature, number of people expected to attend an event, etc.).
These models are based on an input database which can be :
- characteristics,
- historical data (over several years),
- an output data corresponding to the variable you wish to predict.
Classification
Another type of Machine Learning model is classification. The classification algorithms will categorize an individual according to input parameters. A few examples are given below:
- predicting the breed of a dog based on characteristics,
- prediction of the validity or otherwise of a credit application,
- weather prediction (sunny, cloudy or rainy),
- prediction of the operating status of machines, etc.
Thus, the use of Machine Learning (classification and regression in particular) has been democratized in almost all fields: business, weather, finance, commerce, marketing, industry, health, etc.
Some companies hard focus their sales and management strategies on Machine Learning algorithms.
AutoML
The success of Machine Learning has led to a resurgence of data scientists: experts in artificial intelligence, who both elaborate complex mathematical models, and develop its models in order to implement them.
Recently, many AI providers have realized that the expertise required to use Machine Learning was a barrier to its expansion within companies. This is how Auto Machine Learning (AutoML) appeared, designed to make Machine Learning accessible to the greatest number of people, especially developers who do not have any knowledge in mathematics.
AutoML (Automated Machine Learning) allows the support and automation of many steps in the process of creating a Machine Learning model:
- data processing (missing values, duplicates, normalization)
- extraction of labels (characteristics)
- selection of labels
- choice of algorithm and optimization parameters
AutoML permits to a company to realize a Machine Learning project without the expertise of a data scientist or a data science service provider: it thus induces a drastic reduction of the cost of the project. Moreover, the whole issue of production is simplified by the fact that AutoML solution providers ensure the hosting of the model, and the storage of data.
The counterpart of using AutoML is the blur around the algorithm used. There is a “black box” effect, i.e. the user does not have many information about the detailed algorithm and therefore about the explanation of predictions.
Obviously, the use of AutoML is not recommended for all projects. The AutoML has some flaws that force the use of a custom algorithm:

Note that AutoML is not a magic tool either. The major part of the work of a data scientist, although dissociated from mathematics and computer development, is the gathering and formatting of data. This tedious work can only be manual and requires a business expertise (depending on the application domain) that AutoML cannot provide.
Concerning the pricing, all the suppliers provide a similar pricing:
- a payment for model training
- a payment for the deployment of the model according to: the amount of data and/or the number of cores requested
Providers
During our experience on AutoML, we projected ourselves in the role of a company that wants to use Machine Learning to respond to costs prediction and credits classification issues. We embody a company without an AI expert, wishing to obtain a high level of performance at a lower cost, and without using a service provider.
So the first question that comes to mind is: “Which supplier to choose?
So we chose 5 AutoML solution providers:
- Google Cloud AutoML Tables : https://cloud.google.com/automl-tables
- Amazon AWS Machine Learning : https://aws.amazon.com/fr/machine-learning
- Microsoft Automated Machine Learning : https://azure.microsoft.com/en-us/services/machine-learning/automatedml/
- IBM AutoAI : https://www.ibm.com/cloud/watson-studio/autoai
- BigML OptiML : https://bigml.com/whatsnew/optiml
We have tested the 4 solutions of the biggest AI suppliers on the market, and we also wanted to test a solution from a smaller supplier: BigML Opti ML.
Use cases
In order to have a clear vision of the market and the different suppliers, we compared these 5 solutions on two different projects. A classification project and a regression project with other significant differences: database size, number of inputs, domain. We will therefore carry out these two projects to analyse the results of the five suppliers respectively on the two projects.
Regression use case: insurance costs
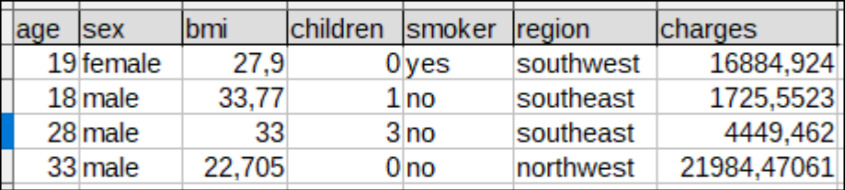
The first project consists in predicting the financial burden that a person will represent for an insurance company. Being an insurance company, the objective is to estimate the cost of each person profile according to parameters / characteristics: age, gender, BMI, number of children, smoker / non-smoker, region. For this purpose, we have a database of 1 339 individuals composed of the inputs mentioned above and the output: charges (cost).
Classification use case: credit validation
The second project aims to predict whether a credit should be accepted or not. In this case, we place ourselves in the position of a bank wishing to develop an automatic model for validating or invalidating credit applications. The objective is to predict yes / no for each credit application according to the following parameters: age, profession, marital status, field of study, credit in default, average annual balance, home loan, personal loan, type of contact, last month of contact in the year, duration of the last contact, number of contacts made during this campaign and for this client, number of days that have passed since the last time the client was contacted in a previous campaign, number of contacts made before this campaign and for this client, result of the previous marketing campaign.
As with the first project, the dataset presents both categorical and numerical data.
We therefore have a database of 45.212 individuals composed of the inputs mentioned above and the output: response (yes / no).

Advantages and disadvantages of the solutions
After having apprehended the 5 solutions on two distinct use cases, some differences appeared between the solutions in the approach and in the use.
First of all to access the service of each provider, the process differs. At Google, you just have to connect to the console and go to the AutoML Tables service and create a dataset. Similarly, you just need to log in to the AWS console and go to Amazon Machine Learning. The Microsoft and IBM cases are more complex. For Microsoft, it is necessary to connect to the Azure portal and then create a new Machine Learning resource. Then you need to log into Microsoft Azure Machine Learning Studio and create a new runtime. The process is not very intuitive, and rather laborious.
Accessing AutoML at IBM is not easy either: connect to Watson Studio, then create a new project, and associate the AutoAI experiment to this project, then choose the instance of Machine Learning (and the associated machine). The step doesn’t seem complex in the explanation, but it is far from being intuitive once on the platform.
The use of BigML does not present any difficulty, it is enough to connect to its dashboard to be able to directly build its model.
Then comes the step of importing the database. At Google and Amazon, the first step is to store the .csv file in a bucket in their Cloud service. Then it can be imported easily, after the creation of a datasource for Amazon.
With Microsoft, you have to create a dataset: import a .csv file, view the imported dataset and eventually change the data type. For IBM, you need to add an “asset” in the project, then import this asset in AutoAI experiment. The BigML interface simply offers to import a data source (our .csv file), then configure it (configure the columns) and import it as a dataset.
Then, whatever the provider, you will have to choose the target data, i.e. the column you want to predict.
Finally, we come to the key stage of the process: the creation and parameterization of the training of the model. Each supplier restricts or allows certain elements of control over the realization of the model, to different degrees:
Google AutoML Tables
Google AutoML Tables leaves the choice to the user, either to use the automatic distribution of the Training / Test split, or to choose this distribution himself. Then the user has different choices to make depending on the type of algorithm involved:
- For a regression, the user will have to choose the optimization parameter on which his model will be based: RMSE (capture the most extreme values with precision), EAM (extreme values will have less impact on the model), RMSLE (penalize the error on the relative size rather than on the absolute value: useful for very high predicted and real values)
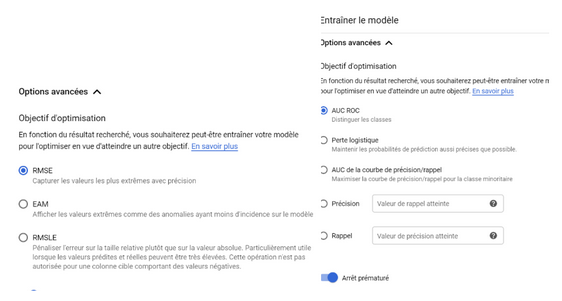
- For a classification, the user will also be able to choose the model optimization parameter: AUC ROC (distinguish classes), Logistic Loss (maintain a high level of accuracy of prediction probabilities), AUC of the accuracy/recall curve (maximize the accuracy/recall curve for the minority class), accuracy (correctly identified proportion of positive identifications), recall (correctly identified proportion of actual positive results).
Google offers the possibility to influence its settings, but the user can use the default choices. For both classification and regression, it is necessary to define the number of drive nodes, and it is possible to exclude columns from the database.
AWS Machine Learning
AWS Machine Learning offers the user two possibilities:
- Default: if the user chooses this option, then he will have a default training report, default training parameters, a training / dataset test distribution at 70% / 30%.
- Custom: the user will be able to choose the maximum size of the model (corresponding to the number of patterns created by the model), the number of iterations (the number of times Amazon ML will analyze the data to find patterns), the type of regularization (to avoid overfitting).
The user will also be able to choose if he wants an automatic split training / test (random or on the last 30% of the dataset) or a manually imported test dataset.
Microsoft Azure Machine Learning
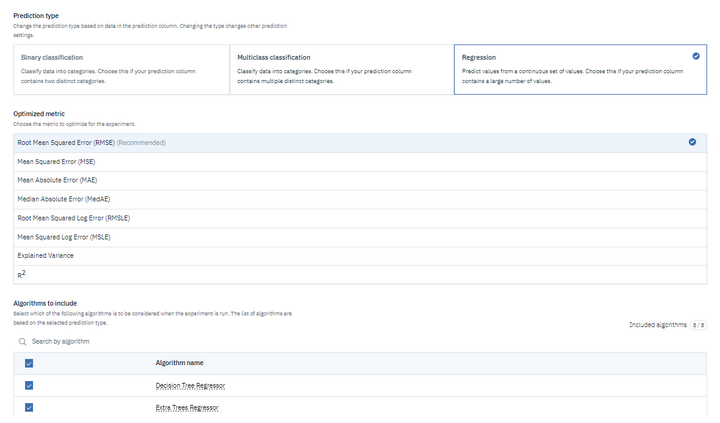
Microsoft Azure Machine Learning uses Scikit Learn’s algorithms, so it creates many models with different algorithms to find the one that gives the best results. This solution allows the user to directly choose the type of algorithm corresponding to the dataset and the problem: classification, regression or timeseries (time series forecasting).
It is possible to choose the main metric to optimize the model, to block some algorithms, to choose the training duration, the number of simultaneous iterations (simultaneous models). The user can also exclude variables or choose the type of validation (Monte-Carlo, cross validation, split validation train).
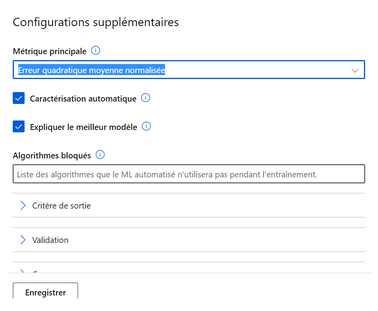
IBM Watson AutoAI Experiment
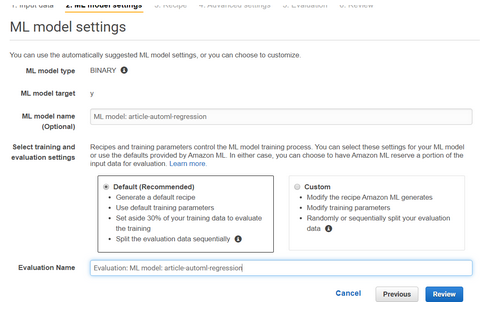
IBM Watson AutoAI Experiment offers the user a setting quite close to Microsoft setting. A choice of the train / test distribution is possible, as well as the exclusion of variables. For prediction, the user can choose between: regression, binary classification and multiclass classification. In addition, it is possible to choose the optimization metrics and exclude algorithms.
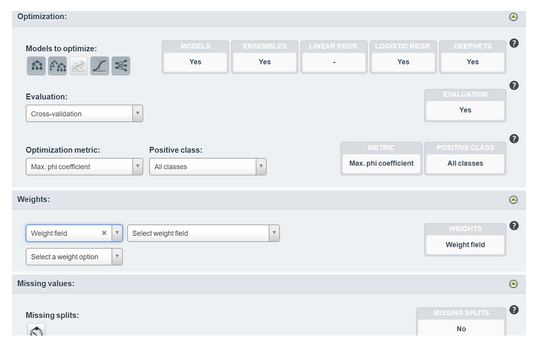
BigML
BigML works very simply but offers less control on the model settings. The user can create an 80%/20% train / test distribution. It is possible to choose the optimization metric of the model, to assign weights to the different classes and also to choose the percentage of dataset samples to be used for the construction of the model.
For example, IBM and Microsoft offer a wide range of settings to customize the model. Google offers slightly fewer settings but they are well detailed and very accessible. BigML offers few configurable options, while Amazon offers accessibility to different settings: not very affordable for novice users who will not have the knowledge or experience to capitalize on these settings.
Evaluation of the model
The model evaluation determines the reliability of the model according to :
- performance criteria representative of the general quality of the model,
- more specific criteria according to the user’s needs.
Some metrics are common to all providers: RMSE for regression and AUC ROC for classification. It is these metrics that we will consider to compare the different solutions.
The RMSE is Root Mean Squared Error. It is the standard deviation of the residuals (prediction errors). The residuals are a measure of the distance of the data points from the regression line.
The formula is :
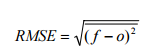
With:
- f = forecasts (expected values or unknown results),
- o = observed values (known results)
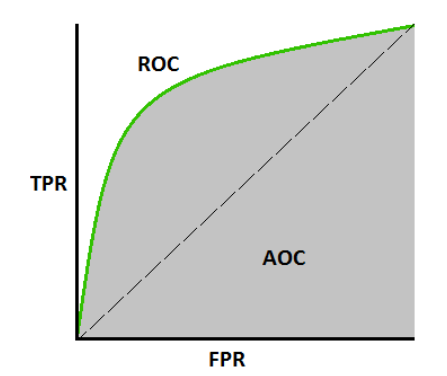
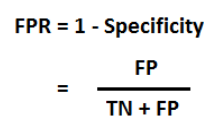
The AUC — ROC curve is a performance measure for classification problems at different thresholds. ROC is a probability curve and AUC is the degree or measure of separability.
The metric used is the area under the curve:
With:

Google, Microsoft and IBM provide a very comprehensive assessment with a large number of metrics and a confusion matrix for classification. BigML provides less result metrics but it is still sufficient. On the other hand, Amazon only displays one concrete metric: RMSE for regression and AUC ROC for classification. While these are the most standard metrics, they may not be sufficient to really evaluate the quality of the model depending on the problem.
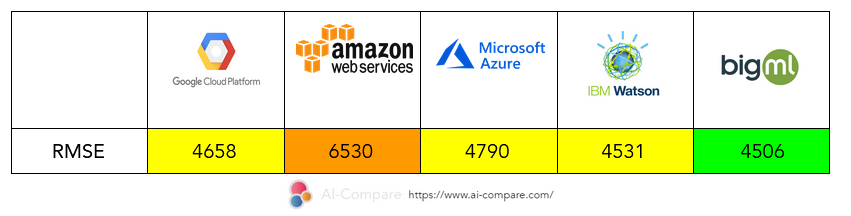
The lower the RMSE is, the better the model performs. So here : BigML > IBM Watson > Google Cloud > Microsoft Azure > Amazon Web Services

The closer to 1 the AUC ROC (area under the curve) is, the better the model performs. So here: IBM Watson > Google Cloud > Microsoft Azure > Amazon Web Services > BigML
Thus, for the insurance cost prediction project, BigML will be preferred. On the other hand, for the credit validation prediction project, BigML has poor performance and IBM and Google will be preferred for this project.
Conclusion
AutoML is better for developers than for data scientists, but these solutions still have real benefits.
For each project, each use case, an analysis is necessary in order to evaluate performances and conditions of use of each solution. It has been observed during this study that each case is specific and that we cannot be sure of the choice of the solution until we have tested several solutions available on the market. Some solutions can bring very poor results, others excellent, and this logic can totally change for another use case. Moreover, depending on the project, priority will be given to costs, results, calculation times and number of requests per second, or ease of use and handling. These are all criteria that can have an impact on the decision, and that allow to choose the solution that best suits the project, the most relevant solution.
It is on this basis that our Eden AI offer comes into play. Thanks to our in-depth expertise in the use of these different Artificial Intelligence solutions, we are able to provide you with the most appropriate recommendation for your problem. Do not hesitate to contact us to describe your need: [email protected]

.jpg)

.jpeg)
.jpeg)