
Summarize this article with:
- Intermodal Relationships: Understanding and capturing relationships between different modalities is essential.
- Fallback provider is the ABCs: You need to set up a provider API that is requested if and only if the main Multimodal Embeddings API does not perform well (or is down).
- Cost - Performance ratio optimization: You can choose the cheapest Multimodal Embeddings provider that performs well for your data.
- Unified API for all providers: simple and standard to use, quick switch between providers, access to the specific features of each provider.
- By benefiting from the support and advice of a team of experts to find the optimal combination of providers according to the specifics of your needs.
What is Multimodal Embeddings API?
A multimodal embeddings API refers to an interface that facilitates the generation of vector representations (embeddings) for multimodal data, incorporating various types of information such as text, images, and possibly other modalities.
Developers can leverage this API to tap into pre-trained models or algorithms designed to adeptly capture semantic relationships within and across various data modes.
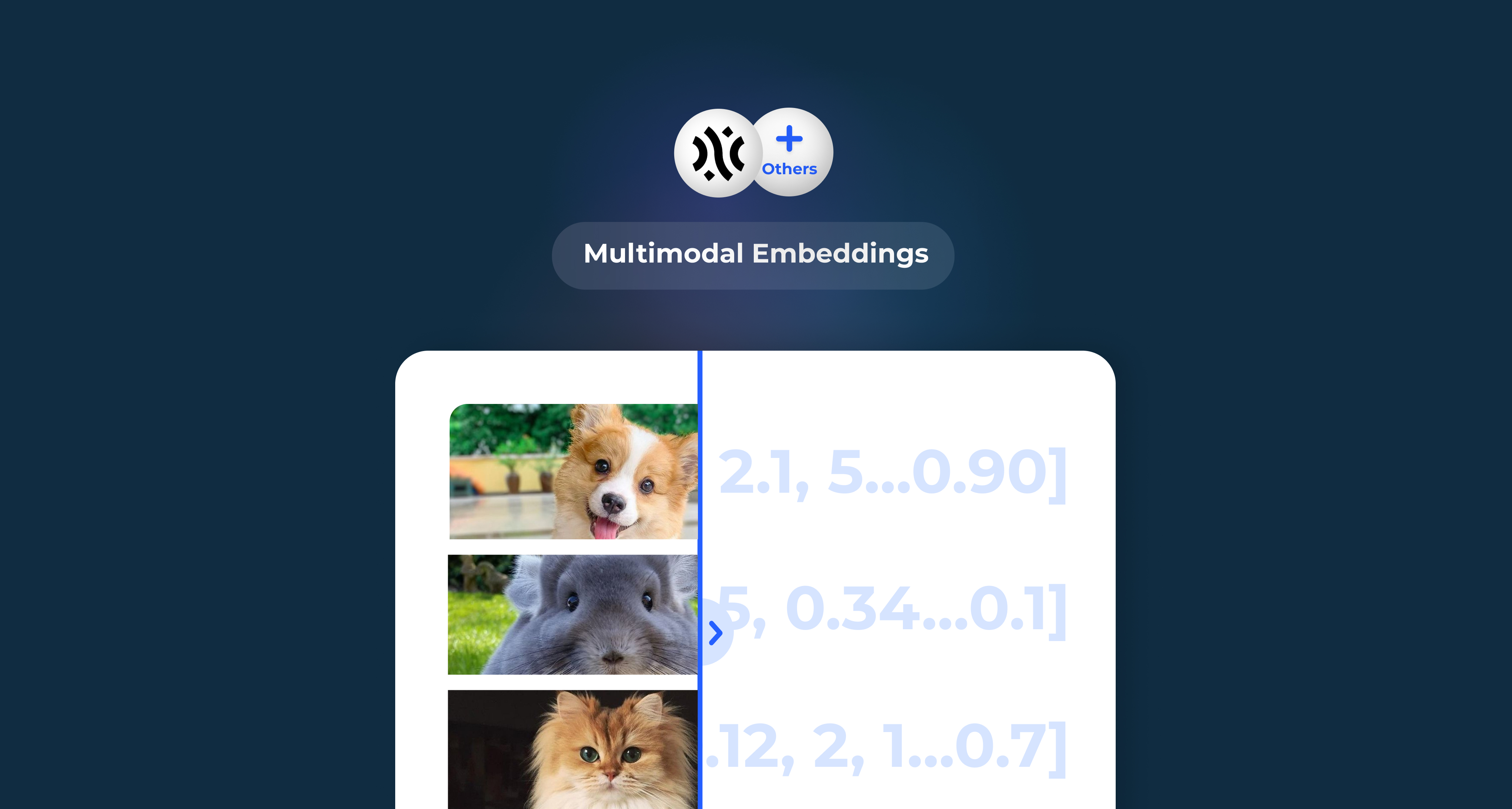
Together, image embeddings and text embeddings form a powerful foundation for applications that require a nuanced understanding of both visual and textual information, fostering a more comprehensive and intelligent approach to data analysis and retrieval.
Applications of multimodal embeddings are diverse and include areas such as image captioning, sentiment analysis on mixed media content, recommendation systems, and various other tasks where understanding and processing information from multiple modalities are essential.

Multimodal Embeddings APIs use cases
You can use Multimodal Embeddings in numerous fields, here are some examples of common use cases:
- Content Understanding: Multimodal embeddings can enhance content understanding by representing the semantics and relationships within text, images, and possibly audio. This is valuable for applications like content recommendation systems, sentiment analysis, and content summarization.
- Visual Question Answering (VQA): Multimodal embeddings can help understand both visual and textual information in scenarios where questions are asked about images. This is useful for applications such as image-based question answering systems and interactive image search.
- Image Captioning: Generating descriptive captions for images requires an understanding of both the visual content and contextual information. Multimodal embeddings aid in aligning image features with corresponding textual descriptions, resulting in more accurate image captioning.
- Interactive Conversational Agents: Chatbots and virtual assistants can use multimodal embeddings to understand and generate responses that consider both text and accompanying images or other modalities. This provides a more engaging conversational experience.
Best Multimodal Embeddings APIs on the market
While comparing Multimodal Embeddings APIs, it is crucial to consider different aspects, among others, cost security and privacy. Multimodal Embeddings experts at Eden AI tested, compared, and used many Multimodal Embeddings APIs of the market. Here are some actors that perform well (in alphabetical order):
- Amazon Titan Multimodal
- Aleph Alpha
- Google Cloud
- Microsoft Azure
- OpenAI
- Replicate
1. Amazon Titan Multimodal
.png)
Amazon Titan Multimodal Embeddings API is a programming interface for multimodal embeddings. It can be used to search for images by text, image, or a combination of text and image.
The API converts images and short English text up to 128 tokens into embeddings that capture semantic meaning and relationships between data. The API generates vectors of 1,024 dimensions that can be used to build search experiences with high accuracy and speed.
2. Aleph Alpha - Available on Eden AI

Aleph Alpha provides multimodal and multilingual embeddings via its API. This technology enables the creation of text and image embeddings that share the same latent space. The Image Embedding API enhances image processing by integrating advanced capabilities to assist with recognition and classification.
The robust algorithms extract rich visual features, providing versatility for applications in various sectors, including e-commerce and content-driven services.
3. Google's Multimodal Embeddings API
.png)
Google's Multimodal Embeddings API generates 1408-dimensional vectors based on input data, which can include images and/or text. These vectors can be used for tasks such as image classification or content moderation.
The image and text vectors are in the same semantic space and have the same dimensionality. Therefore, these vectors can be used interchangeably for tasks such as searching for images using text or searching for text using images.
4. Microsoft Azure's Multimodal embeddings API
Microsoft Azure's Multimodal embeddings API enables the vectorization of both images and text queries. Images are converted to coordinates in a multi-dimensional vector space, and incoming text queries can also be converted to vectors.
Images can then be matched to the text based on semantic closeness, allowing users to search a set of images using text without the need for image tags or other metadata.
5. OpenAI Contrastive Learning In Pretraining (CLIP)
.png)
OpenAI's Contrastive Learning In Pretraining (CLIP) API is capable of comprehending concepts in both text and image formats, and can even establish connections between the two modalities.
This is made possible by the use of two encoder models, one for text inputs and the other for image inputs. These models generate vector representations of the respective inputs, which are then used to identify similar concepts and patterns across both domains using vector search.
6. Replicate's Multimodal embeddings API
Replicate's Multimodal embeddings API is ideal for searching images by text, image, or a combination of text and image. It is designed for high accuracy and fast responses, making it an excellent choice for search and recommendation use cases.

Performance Variations of Multimodal Embeddings
Multimodal Embeddings API performance can vary depending on several variables, including the technology used by the provider, the underlying algorithms, the amount of the dataset, the server architecture, and network latency. Listed below are a few typical performance discrepancies between several Multimodal Embeddings APIs:
- Data Quality and Quantity: The quality and quantity of training data play a significant role in the performance of multimodal embeddings. Insufficient or biased data may result in embeddings that do not generalize well to diverse inputs, leading to suboptimal performance.
- Model Architecture: The choice of the underlying model architecture for generating multimodal embeddings is critical. Different architectures, such as joint embeddings, fusion models, or transformer-based architectures, may yield varying results based on the specific requirements of the task.
- Intermodal Relationships: Understanding and capturing relationships between different modalities is essential. Ensuring that the model can effectively learn and represent the intermodal relationships in the data is critical for optimal performance.
- Domain Specificity: The performance of multimodal embeddings can vary across different domains. Models trained on specific domains may not generalize well to others. Fine-tuning or domain adaptation techniques may be necessary to improve performance in specific application domains.
Why choose Eden AI to manage your Multimodal Embeddings APIs
Companies and developers from a wide range of industries (Social Media, Retail, Health, Finances, Law, etc.) use Eden AI's unique API to easily integrate Multimodal Embeddings tasks in their cloud-based applications, without having to build their solutions.
Eden AI offers multiple AI APIs on its platform among several technologies: Text-to-Speech, Language Detection, Sentiment Analysis, Face Recognition, Question Answering, Data Anonymization, Speech Recognition, and so forth.
We want our users to have access to multiple Multimodal Embeddings engines and manage them in one place so they can reach high performance, optimize cost, and cover all their needs. There are many reasons for using multiple APIs :
- Fallback provider is the ABCs: You need to set up a provider API that is requested if and only if the main Multimodal Embeddings API does not perform well (or is down).
- Performance optimization: After the testing phase, you will be able to build a mapping of providers' performance based on the criteria you have chosen (languages, fields, etc.). Each data that you need to process will then be sent to the best Multimodal Embeddings.
- Cost - Performance ratio optimization: You can choose the cheapest Multimodal Embeddings provider that performs well for your data.
- Combine multiple AI APIs: This approach is required if you look for extremely high accuracy. The combination leads to higher costs but allows your AI service to be safe and accurate because Multimodal Embeddings APIs will validate and invalidate each other for each piece of data.
How Eden AI can help you?
Eden AI is the future of AI usage in companies: our app allows you to call multiple AI APIs.

- Centralized and fully monitored billing on Eden AI for all Multimodal Embeddings APIs.
- Unified API for all providers: simple and standard to use, quick switch between providers, access to the specific features of each provider.
- Standardized response format: the JSON output format is the same for all suppliers thanks to Eden AI's standardization work. The response elements are also standardized thanks to Eden AI's powerful matching algorithms.
- The best Artificial Intelligence APIs in the market are available: big cloud providers (Google, AWS, Microsoft, and more specialized engines).
- Data protection: Eden AI will not store or use any data. Possibility to filter to use only GDPR engines.
Next step in your project
The Eden AI team can help you with your Multimodal Embeddings integration project. This can be done by:
- Organizing a product demo and a discussion to better understand your needs.
- By testing the public version of Eden AI for free: however, not all providers are available on this version. Some are only available on the Enterprise version.
- By benefiting from the support and advice of a team of experts to find the optimal combination of providers according to the specifics of your needs.
- Having the possibility to integrate on a third-party platform: we can quickly develop connectors.

.jpg)
.png)

